Как прочитать свою ДНК-историю: гид по отчетам Familio для поиска предков
Получили результаты генетического теста, но они вызывают лишь вопросы или не сходятся с тем, что вам уже известно о ваших предках? В отчетах Familio по интерпретации данных ДНК-тестов мы не просто выдаем сухие цифры, а проводим настоящее расследование вашего происхождения. В этой статье подробно разберем, что такое этническое происхождение по ДНК, как устроены наши отчеты, на что стоит обратить внимание в первую очередь, как читать карты и диаграммы и почему для некоторых типов отчетов мы просим данные о предках – не чтобы «подогнать» результат, а чтобы сопоставить ваши ожидания с реальными особенностями вашего генома.
Генетическая генеалогия давно доказала, что может помочь в поиске сведений о родственниках и в понимании этнического происхождения. Однако такой поиск предполагает и заметную часть самостоятельной работы – загрузки на сторонние сервисы или обработки с помощью различного программного обеспечения. В особенности такой труд предполагает определение этнического происхождения. «Сырой» результат, который люди видят на сайтах компаний, где сдавали ДНК-тест, не всегда совпадает с ожиданиями из-за собственной референтной базы1 и методики интерпретации этнического происхождения. Поэтому и возникает запрос на интерпретацию результатов ДНК-теста. Это возможность выжать максимум из личной генетической информации.
Familio обладает собственными возможностями для интерпретации ДНК-тестов, используя сервис, который с 2012 года специализируется на исследовании ДНК жителей России и стран СНГ. Он выявляет близость к популяциям или региональным группам, а не к национальностям или лингвистическим группам. Собственную интерпретацию мы предоставляем в виде цифровых отчетов в pdf-формате объемом примерно 15–20 страниц. Результаты, как правило, определяют круг региональных групп, имеющих сходство с геномом заказчика.

Архивы и ДНК-тесты
Как за четыре года составить родословную всех однофамильцев на планете
Виды и структура отчетов Familio
Существуют три вида отчетов Familio: Базовый, Базовый+ и Расширенный. Базовый самый простой, а Расширенный – самый сложный. Однако это не означает, что каждому человеку стоит сразу заказывать Расширенный, чтобы закрыть все вопросы с этническим происхождением. Но и Базового отчета далеко не всем будет достаточно.
Информацию о видах отчетов кратко можно сформулировать так:
- Базовый. Выполняется автоматически специальным алгоритмом. Не требует сведений о предках. Подходит для людей с происхождением от 1-2 этнических групп. Например, если вы знаете, что ваши предки только русские или русские и грузины, то Базовый отчет вполне подойдет. Он также подойдет и тем, кому неизвестно ничего о предках.
- Базовый+. Выполняется экспертом. Требует сведений о предках. Эти сведения нужны, чтобы мы могли сравнить предположения заказчика о собственном происхождении с реальной спецификой генома. Или выяснить происхождение отдельных линий. Подойдет для людей с более сложным происхождением, чем 1-2 этнические группы. Или для тех, кто, имея однородное происхождение, хочет прояснить корни тех или иных линий. Скажем, если у вас в роду евреи, русские и армяне, то стоит заказать именно такой отчет. Другой пример: у вас все предки считались русскими, но три из четырех линий из Курской области, а место рождения дедушки по матери неизвестно. Отчет поможет выяснить, с какими группами русских связано происхождение дедушки. Такой вид отчета мы также рекомендуем людям смешанного славянско-еврейского происхождения – он будет полезней, чем обычный Базовый.
- Расширенный. Выполняется экспертом. Требует сведений о предках. Чаще всего мы рекомендуем его для людей со сложным происхождением от нескольких этнических групп. Но в некоторых случаях подходит и для людей с однородным происхождением. Ключевое отличие от Базового+ заключается в моделировании. Мы не только выявляем особенности генома и описываем их, как в Базовом+, но и проводим серию специальных тестов с вашими данными, чтобы отобрать наиболее подходящие группы, определившие ваше происхождение. Для примера – ваше происхождение связано с русскими, евреями и армянами. В Расширенном отчете мы не только подтверждаем или опровергаем вклад каждой из этих групп, но и ищем конкретные наиболее вероятные группы армян, русских или евреев, которые могли быть связаны с вашими предками.
Универсальными и полезными для большинства пользователей мы считаем отчеты формата Базовый+. Расширенный требуется далеко не всем, а Базовый отчет не всегда может ответить на все вопросы заказчика.
Важно: генетика изучает популяции, а не этносы или национальности. Популяция – это группа людей, проживающих на определенной территории и имеющих общие генетические характеристики. Она может совпадать, а может и не совпадать с этносом, который определяется в первую очередь по самоидентификации. Например, русские Архангельской и Воронежской областей – это представители одного этноса, но двух генетически различающихся популяций. Другой пример – ханты и манси. Два отдельных народа финно-угорской группы из Западной Сибири, но генетических различий между ними очень мало.
Как уже отмечалось, объем отчета немаленький. Но в начале текста есть место, где его выводы кратко сформулированы. Выглядит это примерно как на Рис. 1.

На Рис. 1 мы видим, что у человека алгоритм определил смешанное происхождение. Это означает, что его предки принадлежали по меньшей мере к двум неродственным друг другу группам. Причем определен тип смешанности – 50 на 50. Это предполагает, что его родители принадлежали к разным этносам, точнее, популяциям. В данном случае первая группа связана с финно-угорскими группами – карелами и вепсами – с Северо-Запада России, а вторая – с центральными русскими.
Важное уточнение.
В этом списке группы идут в алфавитном порядке. Скажем, для второго компонента близость русских Ярославской области не меньше, чем русских Ивановской. Но ивановские русские в начале списка лишь потому, что буква «И» ближе к началу алфавита, чем буква «Я». Иногда заказчики на это не обращают внимания и могут считать, что наличие, к примеру, поляков в начале списка обязательно говорит о том, что они ближе всего.
О типе происхождения
Есть два типа происхождения:
● Несмешанный предполагает, что все или почти все предки человека происходили из одной или нескольких схожих групп.
● Смешанный тип подразумевает происхождение ближайших предков человека из разных популяций. Есть несколько сценариев смешанности – 50 на 50, 75 на 25, 87 на 13 (три отличающихся предка). Более мелкий вклад тоже возможно отследить, но уже в отчетах с участием эксперта.
Большая часть отчета посвящена описанию трех этапов исследования, которые основаны на разных методах.
Мы рекомендуем обращать внимание на все три этапа, а также на краткие выводы, которые представлены в начале отчета. Если вы заказали отчет экспертного уровня (Базовый+ или Расширенный), внимательно прочтите текст, выделенный цветом. В нем в доступной форме изложен ход исследования и значимые факты о вашем происхождении, которые удалось выяснить эксперту.
Приведем несколько примеров работы нашего алгоритма на каждом этапе для разных случаев.
Пространство генофондов
Этот этап анализа в отчете основан на методе главных компонентов (principal component analysis, PCA), который позволяет уменьшить размерность данных и увидеть их структуру. С некоторыми оригинальными доработками этот метод позволяет нам вывести популяции Северной Евразии на своеобразный график, генетическую «карту», которую мы называем пространством генофондов. Этносы на нем обозначены цветными пятнами.
Если такое пятно небольшое и ровное – значит, этнос состоит из одной популяции. Если большое, неровное, вытянутое – значит, в составе этого народа несколько разных популяций, плавно перетекающих друг в друга. Некоторые пятна объединяют целую группу генетически схожих или перетекающих друг в друга популяций.
На эту карту – пространство генофондов – алгоритм помещает маркер, соответствующий геному заказчика.
- В Базовом отчете, не требующем сведений о предках, маркер всего один.
- В Базовом+ и Расширенном отчетах два маркера: ожидаемый – по генеалогическим сведениям – и фактический – по ДНК. Они могут разместиться рядом или совпасть в случае полного соответствия предположениям, а могут заметно сместиться в случае каких-либо разночтений ожиданий и реальной специфики.
Рассмотрим на Примере 1. На Рис. 2 первый маркер, показанный красным квадратом, отмечает то положение, где должен находиться геном, исходя из предоставленных нам генеалогических сведений. А красным ромбом обозначено то место, где геном находится по факту результатов анализа ДНК.
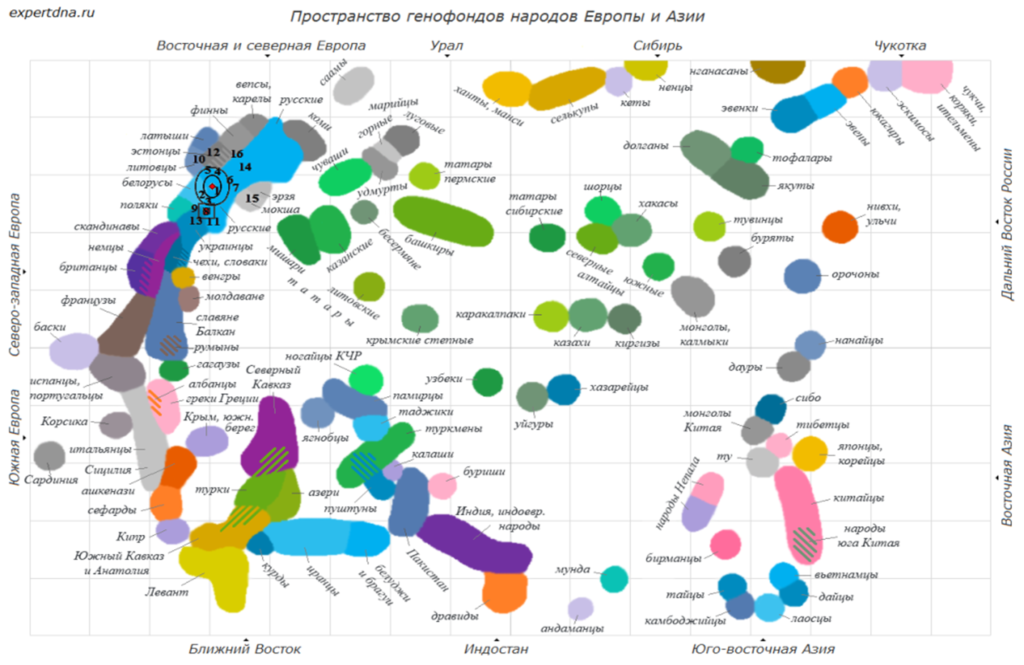
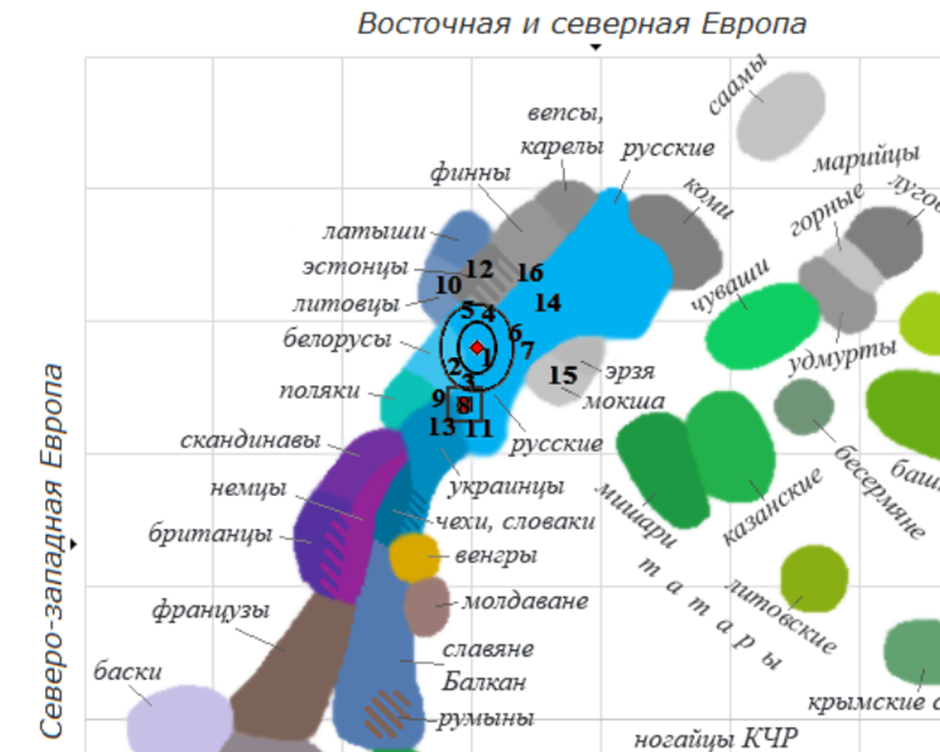
На Примере 1 оба маркера расположились в пределах светло-синего облака, обозначающего русские группы. Однако смещение между двумя значками довольно заметное. Оно означает, что на формирование генома этого человека центральные и северные русские группы оказали большее влияние, чем предполагают генеалогические сведения. Цифрами показаны ближайшие группы, расшифровка дается внутри отчета. Важный момент – в рассматриваемом разделе группы действительно пронумерованы в порядке убывания сходства – от самых близких (группы 1, 2, 3…) до менее близких (группы …14, 15, 16).
Посмотрим на Рис. 3, где нужная нам часть пространства увеличена. Можно рассмотреть поближе оба маркера. Обращаем внимание на два концентрических овала. Мы применяем их в случае, если алгоритм определяет геном как несмешанный – когда несколько поколений жили в одном регионе или среди близких по происхождению групп. Эти овалы отмечают пространство, где с разной вероятностью (50% и 90%) находятся возможные предковые группы. Как видим, в данном случае ожидаемая группа в концентрические овалы не вошла. Таким образом, вероятность, что предки происходят только из изначально указанной популяции, невелика – не более 10%. А значит, происхождение несколько сложнее, чем предполагалось. Хотя и не выходит за рамки русских групп.
Можно заметить, что красный квадрат (предполагаемое происхождение) заключен в квадратные рамки. Так мы обозначаем группы, которые заказчик указал в качестве предковых. В данном случае нам сообщили, что предки связаны с Воронежской областью: цифра 8 на пространстве. При этом подробной генеалогии у человека не было: происхождение дальше бабушек и дедушек оставалось слабоизученным. Анализ на этапе главных компонентов показал, что геном заметно смещен наверх и ближе к центральным русским: цифра 8 – русские Московской, Тверской, Владимирской областей. В дальнейшем собственные генеалогические изыскания заказчика подтвердили, что значительная часть предков действительно была связана с переселенцами из Московской области.
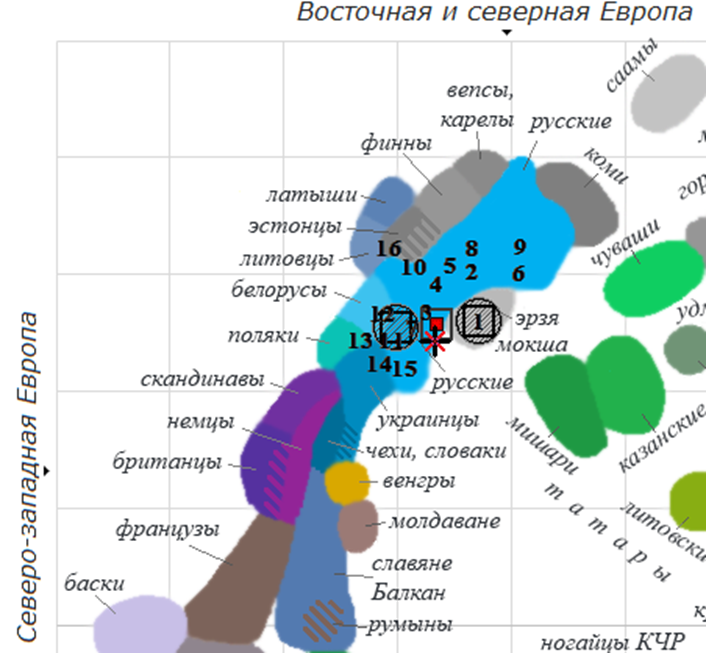
Рассмотрим другой пример, Пример 2 – со смешанной моделью. Здесь мы также видим два маркера – предполагаемого и фактического положений генома. Однако в этом случае они разместились очень близко друг к другу (см. Рис. 4). Настолько близко, что имеющимся небольшим расхождением можно пренебречь. Заказчик отмечал, что его папа имеет русское происхождение (Рязанская область), а мама – мокшанское. Как видим, предположение полностью подтвердилось. Здесь, в отличие от изображения Примера 1, можно увидеть два заштрихованных круга. Это отдельные неродственные предковые компоненты, которые алгоритм выделил внутри генома. И первый из них действительно лег поверх мордовских групп (мокши и эрзи – двух родственных финно-угорских групп), а второй – поверх части южных русских групп, включая рязанцев. Таким образом, в Примере 2 предположения заказчика и полученная нами картина полностью сошлись.
Географические карты
Следующий этап анализа предполагает использование метода IBD (Identity by descent). Его алгоритмы ищут совпадающие участки ДНК, унаследованные от одного и того же предка. Если такие совпадения есть у вас и представителей определенных регионов – значит, вы и жители этого региона имеете общих прародителей. Метод применяется как для поиска близких и дальних родственников, так и для поиска «родственных» популяций.
В Familio IBD доработан и адаптирован к использованию для групп Северной Евразии. Результат выводится на карту, где наиболее интенсивным цветом показаны ближайшие группы. Обычно в отчете представлены 2-3 карты: для Северной Евразии, Восточной Европы и Кавказа.
Рассмотрим один из результатов с несмешанным происхождением, Пример 3. Карта на Рис. 5 слегка отредактирована для лучшей контрастности.
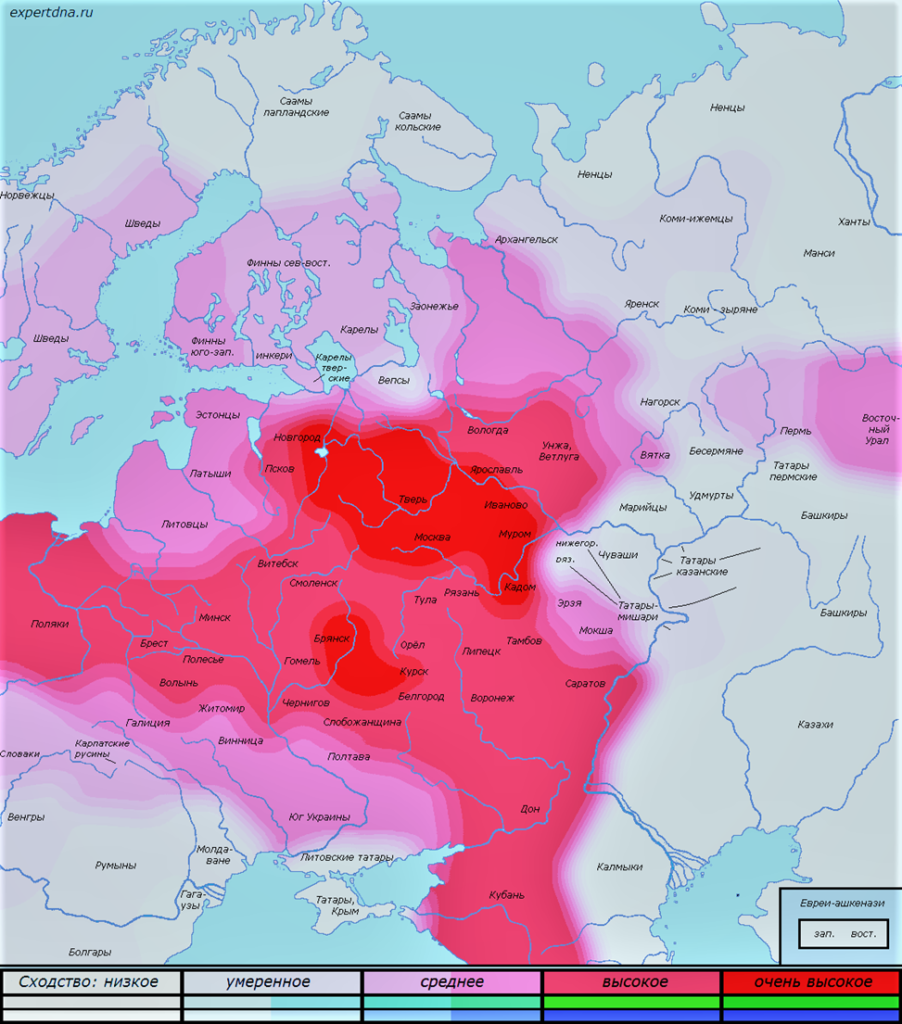
Рис. 5. Пример генетической близости генома на географических картах для несмешанного происхождения. Предоставлено автором статьи
В данном случае наиболее близкие группы объединяют несколько центральных русских групп (Тверская, Московская, Владимирская, Ивановская области, рязанская мещера) и русских Брянской области. Сходство с остальными выражено слабее, что на карте показано более бледными оттенками. При этом даже среди групп с наиболее высоким сходством не все они одинаково близки. В Базовых+ и Расширенных отчетах мы стараемся выделить несколько самых близких групп в тексте. Эта карта отражает близость человека с несмешанным происхождением к группам Восточной Европы.
Теперь рассмотрим Пример 4 смешанного происхождения.
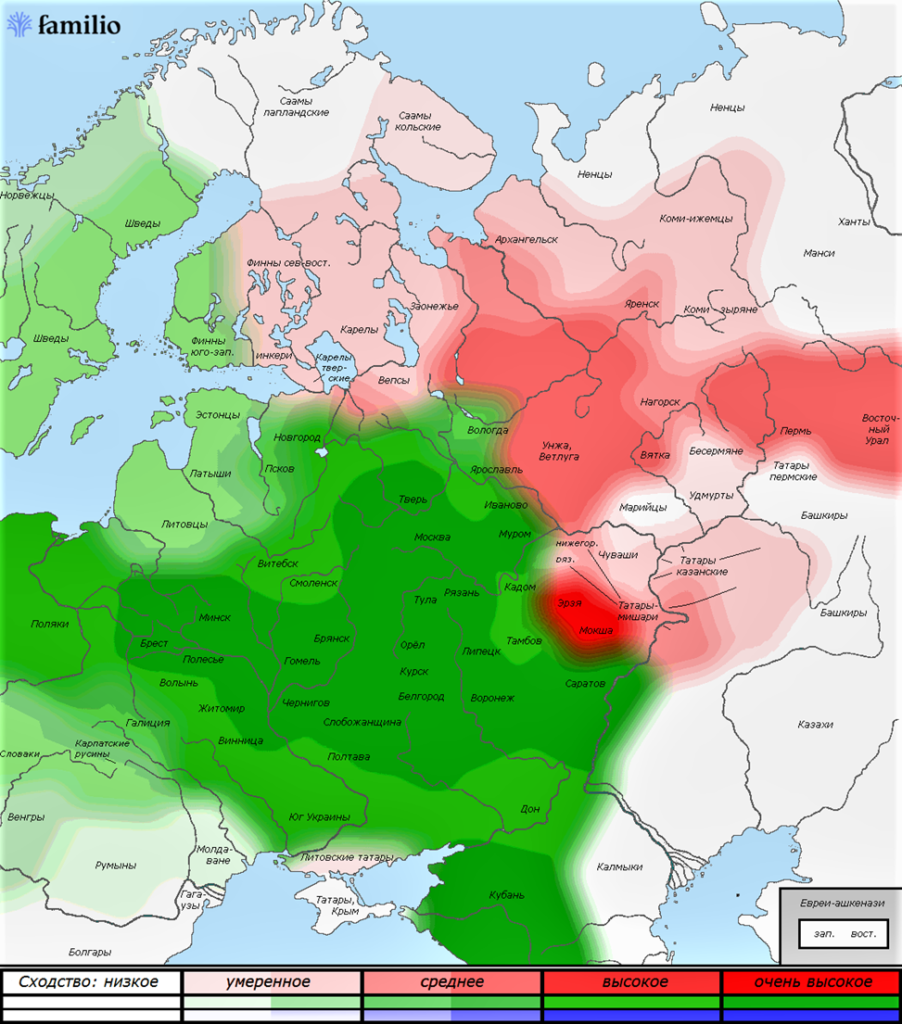
На Рис. 6 представлен случай, который мы уже разбирали на предыдущем этапе в Примере 2 – человек с русско-мокшанским происхождением. Условно «русский» компонент обозначен зеленым цветом. Хотя он объединяет не только русские группы, данные алгоритма показали, что внутри зеленого пятна наиболее близки южные русские, особенно русские Рязанской области. А вот красный компонент, условно «мокшанский», занял более компактную территорию. Ближе всего он к мокше и эрзе, но также показал менее выраженную близость и некоторым северным русским группам.
Базовые предковые компоненты
Переходим к последнему этапу анализа. На этом шаге используется другой научный метод – Admixture. Инструмент основан на поиске скрытых, устойчивых сочетаний аллелей и их кластеров, оценивая пропорции предковых компонентов в геноме индивида, и адаптирован для популяций Северной Евразии. Проще говоря, он выявляет устойчивые сочетания вариантов генов, которые повышены у одних групп и снижены у других.
Familio использует модель из девяти предковых кластеров, условно называемых базовыми предковыми компонентами. Они имеют некоторую корреляцию с реальными древними группами – охотниками, земледельцами каменного века. Но связь здесь непрямая, потому что наши базовые компоненты скорее представляют сочетание влияния древних групп и приобретенных генетических особенностей у современного населения.
Выделившиеся компоненты мы для простоты назвали по регионам, где они преобладают. Например, доля европейского компонента больше всего у народов Северной Европы, особенно у литовцев и латышей. Средиземноморский преобладает в Южной Европе и на Ближнем Востоке. Западносибирский – у хантов и манси, восточносибирский – у нганасан, эвенков, якутов.
На Рис. 7 представлена карта Северной Евразии с семью наиболее распространенными предковыми компонентами. Зоны, где частота компонента повышена, переданы наиболее интенсивным цветом.
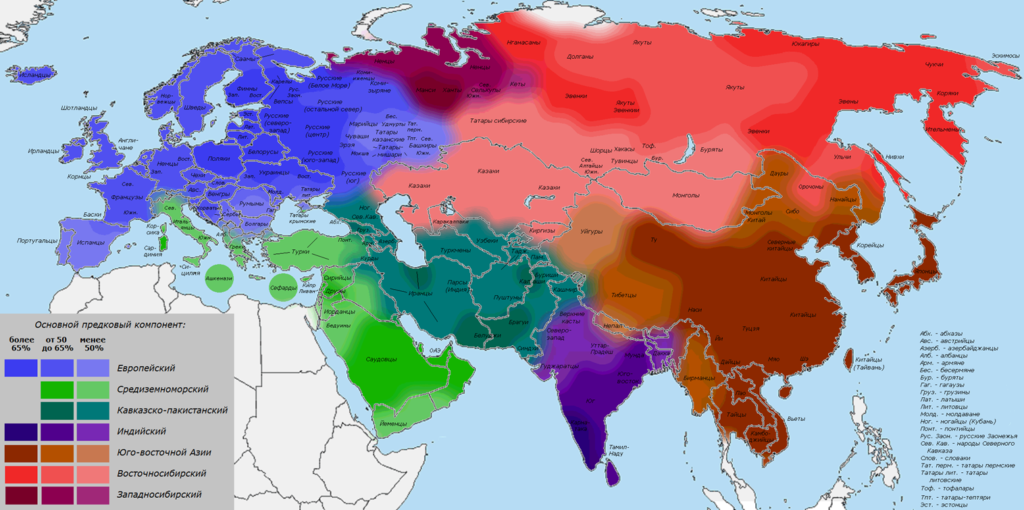
У определенного человека будет выделяться не один компонент, а их совокупность, складываясь в картину, характерную для того или иного региона.
В отчете мы приводим диаграмму со значениями у конкретного заказчика. Пример диаграммы на Рис.8.
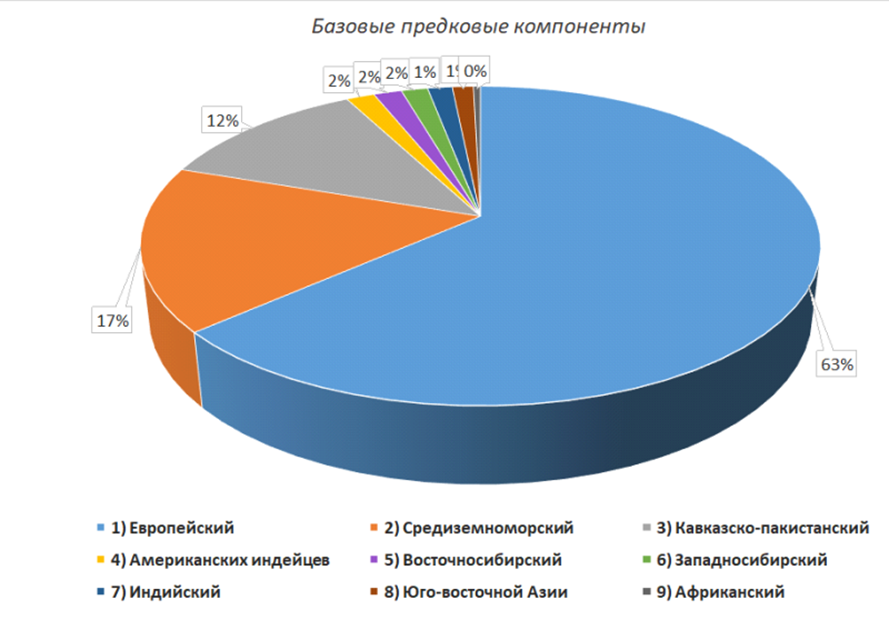
Под диаграммой указываем расшифровку с количественными данными и общей информацией. Как приведенные сведения позволяют уточнять происхождение человека? Дело в том, что величина компонентов может заметно отличаться даже у соседних популяций.
На Рис. 9 можно увидеть несколько диаграмм со значениями, присущими трем группам Восточной Европы.
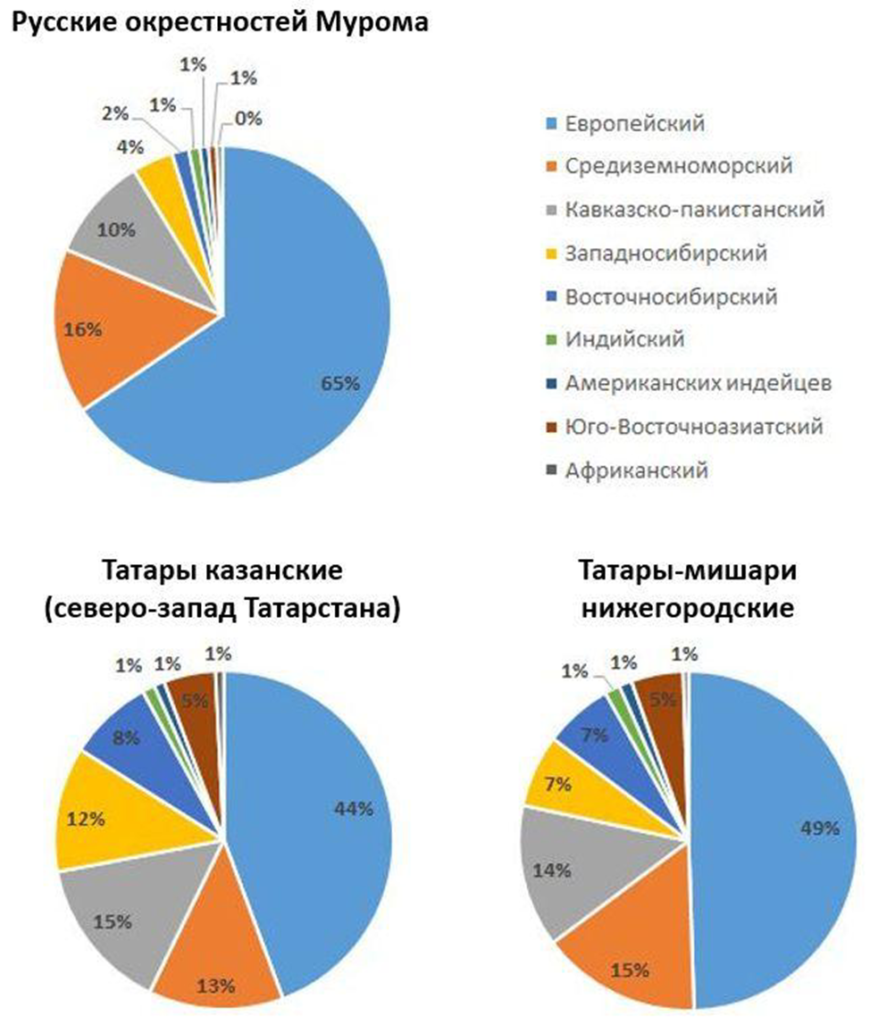
Если посмотреть на показатели, характерные для русских Владимирской области, мы увидим преобладание европейского компонента, некоторый вклад средиземноморского и кавказско-пакистанского и небольшие вклады восточных. Для сравнения взглянем на диаграмму Рис. 9 с показателями северо-западных казанских татар (нижний ряд слева). Здесь картина иная. Европейского заметно меньше, зато повышены сибирский и юго-восточноазиатский.
Однако татарские группы бывают разные. Если мы взглянем на диаграмму для нижегородских мишарей (справа внизу на Рис. 9), то увидим заметные отличия от казанских татар. И действительно, эти две группы по своей генетике различаются. Европейского и средиземноморского несколько больше, а сибирского меньше.
В Базовом+ и Расширенном отчетах мы приводим диаграмму, на которой можно сравнить ожидаемые и фактические показатели компонентов. Пример такой диаграммы приведен на Рис. 10.
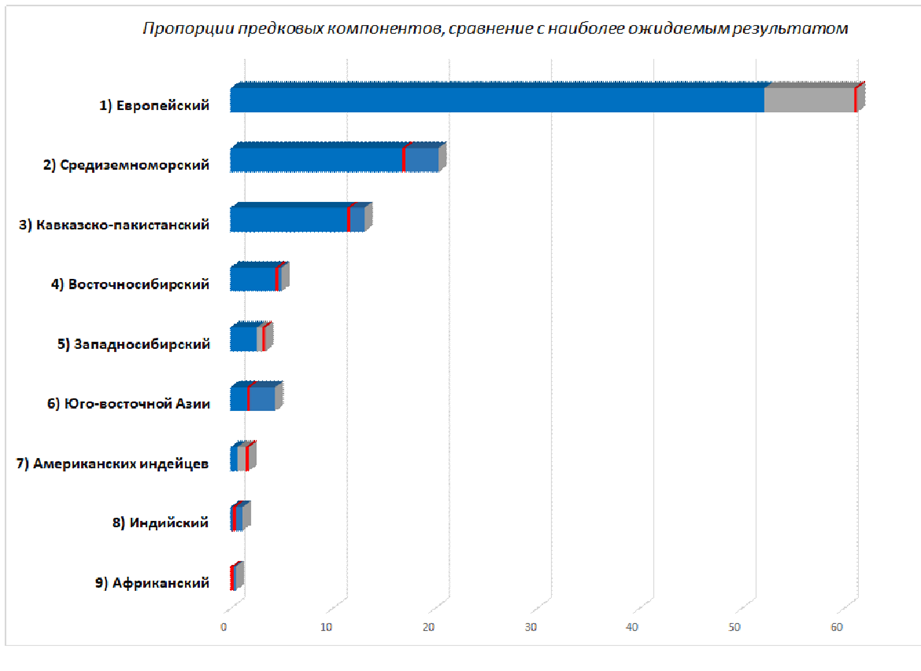
Значение каждого компонента показано в виде горизонтального столбца. Область, закрашенная синим цветом, отражает ожидаемые значения компонента согласно предоставленным генеалогическим данным, а красный «поясок» отмечает фактические значения. На примере Рис. 10 видны заметные увеличения условно северных и уменьшения условно южных компонентов. По семейной легенде предполагалось, что у человека по одной из линий был предок еврей-ашкенази. Фактическая картина говорит об отсутствии значимого вклада евреев и соответствует восточноевропейскому происхождению.
Геномный детектив
Такова – в общих чертах – структура отчета и описание этапов его работы. В Базовых+ и Расширенных отчетах присутствует экспертное заключение. Оно выделяется цветом. В нем доступно описаны вводные данные, сопоставлены ожидаемые и фактические особенности генома, разъясняются результаты каждого этапа анализа. И конечно, дается общий вывод о вероятном популяционном происхождении. Если у заказчика были какие-то вопросы по отдельным линиям или семейным легендам, ответы приводятся именно в заключении.
Для эксперта составление отчета – это своего рода детектив, где он, опираясь на генетические данные-«улики», проверяет гипотезы, отбрасывает ложные версии и находит «недостающие звенья в цепи» истории рода. Для заказчика это всегда способ выжать максимум об этническом происхождении из аутосомного текста.
Завершая статью, не могу не поделиться небольшим наблюдением. Как правило, семейные легенды не так часто подтверждаются, как хотелось бы. Все зависит от исходных данных. Иногда заказчики предполагают, основываясь на стереотипах, что предок мог быть представителем иного этноса, опираясь на воспоминания о его внешности или фотографии. Если слишком темный – значит, цыган или еврей, если светлый – немец или скандинав. Чаще всего подобные предположения не подтверждаются. Когда точно известно, что предок был иностранец, но имеющиеся данные не позволяют определить, из какого именно этноса он происходил, требуется прорабатывать множество гипотез. По мере анализа одни надо отбрасывать, а другие оставлять. Но именно это приближает к пониманию того, как все было на самом деле.

Базовые понятия генетической генеалогии. Первая часть
Первый шаг в генетической генеалогии: основы строения ДНК
- Референтная база – это коллекция эталонных ДНК-профилей, собранных у людей с известным и документально подтвержденным происхождением из конкретных этнических и региональных групп. Именно с этой базой данных сравнивается ДНК тестируемого человека для определения его вероятного генетического происхождения. ↩︎